tg-me.com/machinelearning_interview/1830
Last Update:
Те, кто работает с синтезом речи, знают, что авторегрессионные трансформерные модели, хоть и хороши для генерации речи из текста с нуля, но создают кучу проблем, когда нужно редактирование. Стандартные методы, в виде полной перегенерации предложения, обходятся дорого по ресурсам и часто приводят к изменению интонации или ритма.
Замена отдельного слова обычно оставляет неприятные «склейки» на границах, а перегенерация с середины фразы может испортить уже существующую часть. Все это бьет по естественности и связности звучания.
PlayAI выпустила PlayDiffusion 1.0 – диффузионную модель для редактирования речи, которая умеет изменять нужные участки аудио, сохраняя при этом общую гладкость и характеристики голоса. Причем модель пригодна как для реальной речи, так и для аудио, сгенерированного другими TTS-моделями.
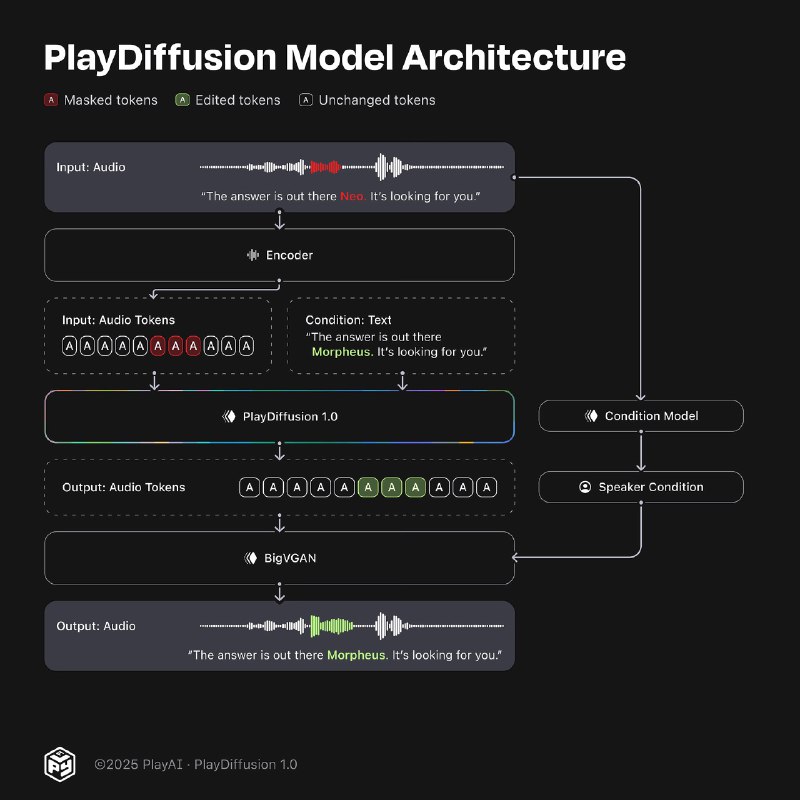
В PlayDiffusion аудиопоток кодируется в дискретное пространство, превращаясь в более компактную последовательность токенов. Затем, тот сегмент, который требует модификации маскируется.
После этого задействуется сама диффузионная модель. Она, опираясь на обновленный текстовый контент, «восстанавливает» замаскированную область, убирая шум. На выходе последовательность токенов снова преобразуется в полноценный звук с помощью декодера BigVGAN.
Чтобы добиться таких результатов, PlayAI взяли за основу текстовую трансформерную архитектуру и внесли несколько ключевых модификаций:
Интересно, что если замаскировать вообще всю аудиодорожку, PlayDiffusion может работать как TTS. В отличие от авторегрессионных моделей, которые генерируют каждый токен последовательно, опираясь на предыдущие, диффузионные модели генерят все токены одновременно, а затем уточняют их за фиксированное число шагов.
Например, для генерации 20 секунд аудио кодеком на 50 Гц авторегрессионной модели потребуется 1000 шагов. PlayDiffusion же способен выдать все 1000 токенов сразу и уточнить их всего за 20 итераций – это до 50 раз эффективнее по количеству шагов генерации.
@ai_machinelearning_big_data
#AI #ML #TTS #Inpainting #PlayDiffusion #PlayAI